Amit ChauhanCreate a Powerful Chatbot on Custom Data using GeminiPro LLMs and LangChain with PythonLearn large language model applications in artificial intelligenceJul 10Jul 10
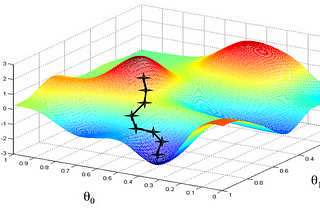
Amit ChauhaninLevel Up CodingFully Explained Gradient Descent for Machine LearningLoss optimization techniques in the machine and deep learningJun 31Jun 31
Amit ChauhanEarly Stopping Callback to Improve Neural Network Performance with PythonHyper-tuning neural network parameters to increase performanceMay 31May 31
Amit ChauhaninTowards AIAWS: Virtual Private Cloud and Load BalancerImprove application performance with reduced latency and high-securityMay 29May 29
Amit ChauhaninThe PythoneersCreate a QA Chatbot with GeminiPro LLM model with Python from PDFGoogle’s large language models in artificial intelligenceMay 16May 16
Amit ChauhaninLevel Up Coding15 Tips to Improve Python Code ReadabilityGood approaches and techniques in pythonMay 13May 13
Amit ChauhaninJavaScript in Plain EnglishHigher Order Arrays in JavaScript with ExamplesArray methods and their operationsMay 8May 8
Amit ChauhanStep-by-Step Guide to Start Prompt Engineering with LangchainProducing a response based on a chain of promptsMay 4May 4
Amit ChauhaninLevel Up Coding10 Types of LLMs to Implement Generative AI ApplicationsDifferent LLM models using langchainMay 3May 3
Amit ChauhaninLevel Up CodingIn-Depth Linux Commands: Zero to HeroBasics to advance for dynamic programmingApr 301Apr 301